Mysql���ݿ��Ż�������֪����
����ʱ�䣺2023-08-24 ��Դ������վ������������������������
[ժҪ]���죬���ݿ�IJ���Խ��Խ��Ϊ����Ӧ�õ�����ƿ���ˣ�������WebӦ���������ԡ��������ݿ�����ܣ��Ⲣ��ֻ��DBA����Ҫ���ĵ��£�����������dz���Ա��Ҫȥ��ע��������죬���ݿ�IJ���Խ��Խ��Ϊ����Ӧ�õ�����ƿ���ˣ�������WebӦ���������ԡ��������ݿ�����ܣ��Ⲣ��ֻ��DBA����Ҫ���ĵ��£��������...
���죬���ݿ�IJ���Խ��Խ��Ϊ����Ӧ�õ�����ƿ���ˣ�������WebӦ���������ԡ��������ݿ�����ܣ��Ⲣ��ֻ��DBA����Ҫ���ĵ��£�����������dz���Ա��Ҫȥ��ע������
���죬���ݿ�IJ���Խ��Խ��Ϊ����Ӧ�õ�����ƿ���ˣ�������WebӦ���������ԡ��������ݿ�����ܣ��Ⲣ��ֻ��DBA����Ҫ���ĵ��£�����������dz���Ա��Ҫȥ��ע�����顣������ȥ������ݿ����ṹ���Բ������ݿ�ʱ�������Dz��ʱ��SQL��䣩�����Ƕ���Ҫע�����ݲ��������ܡ�������Dz��ὲ�����SQL�����Ż�����ֻ�����MySQL��һWebӦ���������ݿ⡣
mysql�������Ż���һ�����ͣ�����һ��һ�����������Ӹ�����������Ż����������ܾͻ��д��������
Mysql���ݿ����Ż�����
��mysql�Ż���һ���ۺ��Եļ�������Ҫ����
?������ƺ�����(����3NF)
?�����ʵ�����(index) [����: ��ͨ����������������Ψһ����unique��ȫ������]
?�ֱ�����(ˮƽ�ָ��ֱ�ָ�)
?��д[д: update/delete/add]����
?�洢���� [ģ�黯��̣���������ٶ�]
?��mysql�����Ż� [���������my.ini, ���������С ]
?mysql������Ӳ������
?��ʱ��ȥ�������Ҫ������,��ʱ������Ƭ����(MyISAM)
���ݿ��Ż�����
����һ��������Ϊ���ĵ�Ӧ�ã����ݿ�ĺû�ֱ��Ӱ�쵽��������ܣ�������ݿ�����������Ҫ��һ����˵��Ҫ��֤���ݿ��Ч�ʣ�Ҫ���������ĸ�����Ĺ�����
�� ���ݿ����
�� sql����Ż�
�� ���ݿ��������
�� ǡ����Ӳ����Դ�Ͳ���ϵͳ
���⣬ʹ���ʵ��Ĵ洢���̣�Ҳ���������ܡ�
���˳��Ҳ���������ĸ�����������Ӱ��Ĵ�С
���ݿ�����
ͨ������������ʽ���������ݿ���ƴ��кô��������ݿ�����У�Ϊ�˸��õ�Ӧ��������ʽ���ͱ���ͨ������������ʽ(ͨ
�������ǹ��õ����⣬���������ѧ��ȷ������)��
��һ��ʽ��1NF�Ƕ����Ե�ԭ����Լ����Ҫ������(��)����ԭ���ԣ������ٷֽ⣻(ֻҪ����ϵ�����ݿ�������1NF)
�ڶ���ʽ��2NF�ǶԼ�¼��Ωһ��Լ����Ҫ���¼��Ωһ��ʶ����ʵ���Ωһ�ԣ�
������ʽ��3NF�Ƕ��ֶ������Ե�Լ������Ҫ���ֶ�û�����ࡣ û����������ݿ���ƿ���������
���ǣ�û����������ݿ�δ������õ����ݿ⣬��ʱΪ���������Ч�ʣ��ͱ��뽵�ͷ�ʽ�����ʵ������������ݡ����������ǣ� �ڸ�������ģ�����ʱ���ص�����ʽ�����ͷ�ʽ���Ĺ����ŵ���������ģ�����ʱ���ǡ����ͷ�ʽ���������ֶΣ��������ࡣ
? ���ݿ�ķ���
��ϵ�����ݿ�: mysql/oracle/db2/informix/sysbase/sql server
�ǹ�ϵ�����ݿ�: (�ص�: �������������)
NoSql���ݿ�: MongoDB(�ص��������ĵ�)
����˵��ʲô���ʶ����࣬����˵�����ɵ�����!
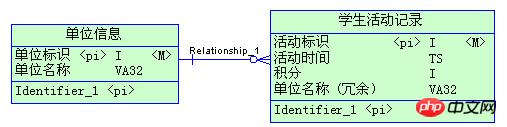
����������Dz����ʵ����࣬ԭ����:
�����Ϊ�����ѧ�����¼�ļ���Ч�ʣ��ѵ�λ�������ൽѧ�����¼�����λ��Ϣ��500����¼����ѧ�����¼��
һ���ڴ����200���������� ���ѧ�����¼�������������λ�����ֶΣ�ֻ��������int�ֶκ�һ��timestamp�ֶΣ�ֻռ����16�ֽڣ���һ����С�ı�����������һ�� varchar(32)���ֶκ�����ԭ����3��������������ӦҲ������ô���I/O�����Ҽ�¼��������⣬500 VS 2000000 �����¸���һ����λ���ƻ�Ҫ����4000�������¼���ɴ˿ɼ������������������ʵ��䷴��
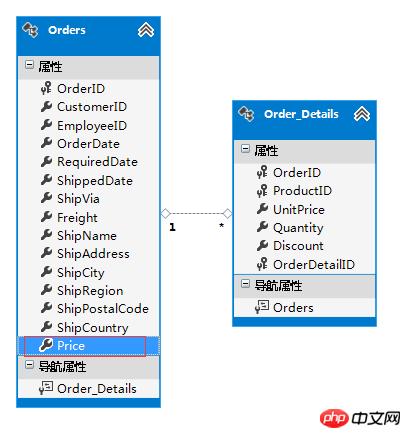
�����������Price����һ�������ֶΣ���Ϊ���ǿ��ԴӶ�����ϸ����ͳ�Ƴ���������ļ۸�����������Ǻ����ģ�Ҳ��������ѯ���ܡ�
���������������п��Եó�һ������:
1---n ����Ӧ��������1��һ��.
SQL����Ż�
SQL�Ż���һ�㲽��
1.ͨ��show status�����˽����SQL��ִ��Ƶ�ʡ�
2.��λִ��Ч�ʽϵ͵�SQL���-���ص�select��
3.ͨ��explain������Ч�ʵ�SQL
4.ȷ�����Ⲣ��ȡ��Ӧ���Ż���ʩ
-- select������
Select
Dml���ݲ�������(insert update delete)
dtl ������������(commit rollback savepoint)
Ddl���ݶ�������(create alter drop..)
Dcl(���ݿ�������) grant revoke
-- Show status ��������
--��ѯ���λỰ
Show session status like 'com_%'; //show session status like 'Com_select'
--��ѯȫ��
Show global status like 'com_%';
-- ��ij���û���Ȩ
grant all privileges on *.* to 'abc'@'%';
--Ϊʲô������Ȩ 'abc'?��ʾ�û��� '@' ��ʾhost, �鿴һ��mysql->user����֪����
--����Ȩ��
revoke all on *.* from 'abc'@'%';
--ˢ��Ȩ��[Ҳ���Բ�д]
flush privileges;
SQL����Ż�-show����
MySQL�ͻ������ӳɹ���ͨ��ʹ��show [session global] status ��������ṩ������״̬��Ϣ�����е�session����ʾ��ǰ�����ӵ�ͳ�ƽ����global����ʾ�����ݿ��ϴ����������ͳ�ƽ����Ĭ����session����ġ�
��������ӣ�
show status like 'Com_%';
����Com_XXX��ʾXXX�����ִ�еĴ�����
�ص�ע�⣺Com_select,Com_insert,Com_update,Com_deleteͨ���⼸�����������������˽��ǰ���ݿ��Ӧ�����Բ������Ϊ�������Բ�ѯ����Ϊ�����Լ������SQL���µ�ִ�б����Ƕ��١�
���м������õIJ��������û��˽����ݿ�Ļ��������
Connections����ͼ����MySQL�������Ĵ���
Uptime��������������ʱ�䣨��λ�룩
Slow_queries������ѯ�Ĵ��� (Ĭ��������ѯʱ��10s)
show status like 'Connections'
show status like 'Uptime'
show status like 'Slow_queries'
��β�ѯmysql������ѯʱ��
Show variables like 'long_query_time';
��mysql ����ѯʱ��
set long_query_time=2
SQL����Ż�-��λ����ѯ
�����ǣ� ��δ�һ������Ŀ�У�Ѹ�ٵĶ�λִ���ٶ��������. (��λ����ѯ)
���������˽�mysql���ݿ��һЩ����״̬��β�ѯ(������֪����ǰmysql���е�ʱ��/һ��ִ���˶��ٴ�
select/update/delete.. / ��ǰ����)
Ϊ�˱��ڲ��ԣ����ǹ���һ�����(400 ��)-> ʹ�ô洢��������
Ĭ������£�mysql��Ϊ10�����һ������ѯ.
��mysql������ѯ.
show variables like 'long_query_time' ; //������ʾ��ǰ����ѯʱ��
set long_query_time=1 ;//����������ѯʱ��
�������->����м�¼��Ҫ��, ��¼�Dz�ͬ�����ã��������Ч������ʵ������.����:
CREATE TABLE dept( /*���ű�*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*���*/
dname VARCHAR(20) NOT NULL DEFAULT "", /*����*/
loc VARCHAR(13) NOT NULL DEFAULT "" /*�ص�*/
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE emp
(empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*���*/
ename VARCHAR(20) NOT NULL DEFAULT "", /*����*/
job VARCHAR(9) NOT NULL DEFAULT "",/*����*/
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*�ϼ����*/
hiredate DATE NOT NULL,/*��ְʱ��*/
sal DECIMAL(7,2) NOT NULL,/*нˮ*/
comm DECIMAL(7,2) NOT NULL,/*����*/
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*���ű��*/
)ENGINE=MyISAM DEFAULT CHARSET=utf8 ;
CREATE TABLE salgrade
(
grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
losal DECIMAL(17,2) NOT NULL,
hisal DECIMAL(17,2) NOT NULL
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
��������
INSERT INTO salgrade VALUES (1,700,1200);
INSERT INTO salgrade VALUES (2,1201,1400);
INSERT INTO salgrade VALUES (3,1401,2000);
INSERT INTO salgrade VALUES (4,2001,3000);
INSERT INTO salgrade VALUES (5,3001,9999);
Ϊ�˴洢�����ܹ�����ִ�У�������Ҫ������ִ�н�������delimiter $$
�����������ú����᷵��һ��ָ�����ȵ�����ַ���
create function rand_string(n INT)
returns varchar(255) #�ú����᷵��һ���ַ���
begin
#chars_str����һ������ chars_str,������ varchar(100),Ĭ��ֵ'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare chars_str varchar(100) default
'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
declare return_str varchar(255) default '';
declare i int default 0;
while i < n do
set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1));
set i = i + 1;
end while;
return return_str;
end
����һ���洢����
create procedure insert_emp(in start int(10),in max_num int(10))
begin
declare i int default 0;
#set autocommit =0 ��autocommit���ó�0
set autocommit = 0;
repeat
set i = i + 1;
insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand());
until i = max_num
end repeat;
commit;
end
#���øո�д�õĺ���, 1800000����¼,��100001�ſ�ʼ
call insert_emp(100001,4000000);
��ʱ�����������һ�����ִ��ʱ�䳬��1���У��ͻ�ͳ�Ƶ�.
���������ѯ��sql��¼�����ǵ�һ����־��
��Ĭ������£��Ͱ汾��mysql�����¼����ѯ����Ҫ������mysqlʱ��ָ����¼����ѯ�ſ���
bin\mysqld.exe - -safe-mode - -slow-query-log [mysql5.5 ������my.iniָ��]
bin\mysqld.exe �Clog-slow-queries=d:/abc.log [�Ͱ汾mysql5.0������my.iniָ��]
������ѯ��־�����dataĿ¼��[��mysql5.0����汾��ʱ���� mysql��װĿ¼/data/��],�� mysql5.5.19������Ҫ�鿴
my.ini �� datadir="C:/Documents and Settings/All Users/Application Data/MySQL/MySQL Server 5.5/Data/����ȷ��.
��mysql5.6�У�Ĭ����������¼����ѯ�ģ�my.ini������Ŀ¼Ϊ��C:\ProgramData\MySQL\MySQL Server 5.6��������һ��������
slow-query-log=1
��� mysql5.5��������ѯ�����ַ���
bin\mysqld.exe - -safe-mode - -slow-query-log
Ҳ������my.ini �ļ�������:
[mysqld]
# The TCP/IP Port the MySQL Server will listen on
port=3306
slow-query-log
ͨ������ѯ��־��λִ��Ч�ʽϵ͵�SQL��䡣����ѯ��־��¼������ִ��ʱ�䳬��long_query_time�����õ�SQL��䡣
show variables like 'long_query_time';
set long_query_time=2;
Ϊdept����������
desc dept;
ALTER table dept add id int PRIMARY key auto_increment;
CREATE PRIMARY KEY on dept(id);
create INDEX idx_dptno_dptname on dept(deptno,dname);
INSERT into dept(deptno,dname,loc) values(1,'�з���','����ʢ����5¥501');
INSERT into dept(deptno,dname,loc) values(2,'��Ʒ��','����ʢ����5¥502');
INSERT into dept(deptno,dname,loc) values(3,'����','����ʢ����5¥503');UPDATE emp set deptno=1 where empno=100002;
****�������***[��emp���ļ�¼����Ϊ3600000 ,Ч����������]
select * from emp where empno=(select empno from emp where ename='���')
�������order by e.empno �ٶȾͻ��������ʱ�ᵽ1min��.
�������
select * from emp e,dept d where e.empno=100002 and e.deptno=d.deptno;
�鿴����ѯ��־��Ĭ��Ϊ����Ŀ¼data�е�host-name-slow.log���Ͱ汾��mysql��Ҫͨ���ڿ���mysqlʱʹ��- -log-slow-queries[=file_name]������
SQL����Ż�-explain��������
Explain select * from emp where ename=��wsrcla��
�����������Ϣ��
select_type:��ʾ��ѯ�����͡�
table:���������ı�
type:��ʾ������������
possible_keys:��ʾ��ѯʱ������ʹ�õ�����
key:��ʾʵ��ʹ�õ�����
key_len:�����ֶεij���
rows:ɨ���������(���������)
Extra:ִ�������������˵��

explain select * from emp where ename='JKLOIP'
���Ҫ����Extra��filesort���Զ�����������
explain select * from emp order by ename\G
EXPLAIN���
id
SELECTʶ���������SELECT�IJ�ѯ���к�
id ʾ��
SELECT * FROM emp WHERE empno = 1 and ename = (SELECT ename FROM emp WHERE empno = 100001) \G;
select_type
PRIMARY :�Ӳ�ѯ��������ѯ
SUBQUERY : �Ӳ�ѯ�ڲ��һ��SELECT��������������ⲿ��ѯ
DEPENDENT SUBQUERY:�Ӳ�ѯ�ڲ��һ��SELECT���������ⲿ��ѯ
UNION :UNION����еڶ���SELECT��ʼ��������SELECT��
SIMPLE
UNION RESULT UNION �кϲ����
Table
��ʾ��һ�����������ݿ��б�����
Type
�Ա����ʷ�ʽ
ALL��
SELECT * FROM emp \G
�����ı�ɨ�� ͨ������
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system��������һ��(=ϵͳ��)������const�������͵�һ����
const���������һ��ƥ����
Possible_keys
�ò�ѯ�������õ����������û���κ�������ʾ null
Key
Mysql �� Possible_keys ��ѡ��ʹ������
Rows
��������������
Extra
��ѯϸ����Ϣ
No tables ��Query�����ʹ��FROM DUAL ���κ�FROM�Ӿ�
Using filesort ����Query��� ORDER BY ���������������������������
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
ͨ���ռ�ͳ����Ϣ�����ܴ��ڽ��
Using temporary��ijЩ��������ʹ����ʱ�������� GROUP BY ; ORDER BY
Using where�����ö�ȡ����������Ϣ����ͨ�������Ϳ��Ի�ȡ��������;
���Ͼ���Mysql���ݿ������Ż���֪���𣿵���ϸ���ݣ��������עphp����������������£�
ѧϰ�̳̿������մ����ŵ���ͨ��SQL֪ʶ��
