- 1PS提示:因为图层已锁定,无法编辑图层的处理方法
- 2picacg苹果版怎么找不到|picacg ios版是不是下架了介绍
- 3Adobe Illustrator CS5 序列号大全
- 4ACDsee注册码免费分享(含ACDsee18、ACDsee10等版本)
- 5Potato(土豆聊天)怎么换头像|Potato app更改头像方法介绍
- 6PDF浏览器能看3D文件吗?PDF浏览器看3D文件图文详细教程
- 7Potato(马铃薯聊天)怎么注册不了|Potato不能注册处理方法介绍
- 8最新的Adobe Illustrator CS4序列号大全
- 9Intel i7-9700K性能跑分曝光:同代提升约12%
- 10XP系统怎么清除缓存?
- 11qq邮件是否已读怎么看 QQ邮箱已经发出去的邮件怎么知道对方是否已经查看
- 12Intel Z390主板有望10月8日公布:8核9代酷睿随后登场
[摘要]断点续传在现在用得很普遍了,如果没有断点续传,那么下载的东西已经下载了90%,但是中断了下载过程,就要从头开始下载。本文就来简单介绍一下Linux系统中断点续传是怎么实现的。断点续传的原理其实断点续...
断点续传在现在用得很普遍了,如果没有断点续传,那么下载的东西已经下载了90%,但是中断了下载过程,就要从头开始下载。本文就来简单介绍一下Linux系统中断点续传是怎么实现的。
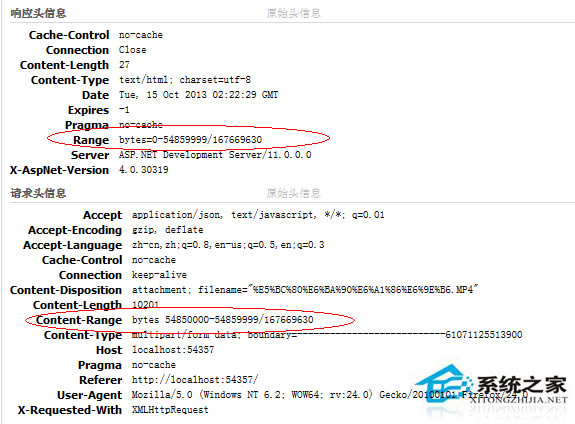
断点续传的原理
其实断点续传的原理很简单,就是在 Http 的请求上和一般的下载有所不同而已。
打个比方,浏览器请求服务器上的一个文时,所发出的请求如下:
假设服务器域名为 wwww.sjtu.edu.cn,文件名为 down.zip。
GET /down.zip HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-
excel, application/msword, application/vnd.ms-powerpoint, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
Connection: Keep-Alive
服务器收到请求后,按要求寻找请求的文件,提取文件的信息,然后返回给浏览器,返回信息如下:
200
Content-Length=106786028
Accept-Ranges=bytes
Date=Mon, 30 Apr 2001 12:56:11 GMT
ETag=W/“02ca57e173c11:95b”
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:56:11 GMT
所谓断点续传,也就是要从文件已经下载的地方开始继续下载。所以在客户端浏览器传给 Web 服务器的时候要多加一条信息 -- 从哪里开始。
下面是用自己编的一个“浏览器”来传递请求信息给 Web 服务器,要求从 2000070 字节开始。
GET /down.zip HTTP/1.0
User-Agent: NetFox
RANGE: bytes=2000070-
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
仔细看一下就会发现多了一行 RANGE: bytes=2000070-
这一行的意思就是告诉服务器 down.zip 这个文件从 2000070 字节开始传,前面的字节不用传了。
服务器收到这个请求以后,返回的信息如下:
206
Content-Length=106786028
Content-Range=bytes 2000070-106786027/106786028
Date=Mon, 30 Apr 2001 12:55:20 GMT
ETag=W/“02ca57e173c11:95b”
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:55:20 GMT
和前面服务器返回的信息比较一下,就会发现增加了一行:
Content-Range=bytes 2000070-106786027/106786028
返回的代码也改为 206 了,而不再是 200 了。
知道了以上原理,就可以进行断点续传的编程了。
Linux是一套免费使用和自由传播的类Unix操作系统
推荐资讯 总人气榜
最新教程 本月人气
- 1苹果电视什么时候上市?苹果电视上市时间
- 2正在iphone6上使用qq去掉/取消图文说明教程
- 3macbook air 2015价格多少钱?苹果2015版macbook air报价
- 4macbook air 2015型号是多少?苹果2015版macbook air型号
- 5iphone微信6.1下载地址 苹果ios微信6.1官方下载
- 6apple watch首批上市国家:苹果自动选择手表首批发售地区
- 7apple watch国行什么时候上市?苹果apple watch国内上市时间
- 8apple watch国行价格多少钱?苹果apple watch自动选择手表国行报价
- 912306手机版在什么地方下载?安卓/iphone12306手机版官方下载
- 10160wifi ios版怎么用?iphone/ipad版160wifi使用图文说明教程
- 11iphone6s、索尼xperia z5与3星galaxy s6指纹解锁比较视频
- 12ios9不越狱怎么恢复短信与照片 ios9不越狱恢复短信与照片图文说明教程
- 1猎豹浏览器抢票不受12306新版验证码影响
- 2抱抱app怎么玩 抱抱app使用图文说明教程图
- 3360手机助手红包怎么提现 360手机助手红包提现设置流程
- 4160wifi远程桌面怎么连接 160wifi远程桌面连接设置方法
- 5抱抱app免费随机通话使用图文说明教程(图文流程)
- 6微信PC版1.0.7.33官方下载公布 修好bug优化软件
- 7部落冲突安卓版与苹果版是关联的吗 安卓版与ios版可以一起玩吗_绿茶安卓网
- 8hypersnap怎么连续截图 hypersnap连续截图设置图文说明教程
- 9百度docs怎么用 百度docs在线处理工具使用图文说明教程
- 10小皮助手安装失败怎么办 小皮助手安卓模拟器安装失败处理方法
- 11微信购物圈怎么用 微信购物圈使用方法介绍
- 12小皮助手下载引擎失败怎么办 小皮助手下载引擎失败处理方案
